
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- test-helper
- 머신러닝
- 이것이 코딩테스트다 with 파이썬
- CS231n
- SWEA
- 전산기초
- MySQL
- 자료구조 및 실습
- 코드수행
- 그리디
- C++
- 모두를 위한 딥러닝 강좌 시즌1
- 백준
- 파이썬
- pytorch
- Object detection
- 딥러닝
- 실전알고리즘
- ssd
- Python
- docker
- 구현
- ubuntu
- AWS
- cs
- 3단계
- STL
- 2단계
- 프로그래머스
- 1단계
- Today
- Total
곰퓨타의 SW 이야기
Lab 09-3 Dropout 본문
부스트코스 강의를 수강중이다!!!
www.boostcourse.org/ai214/lecture/43761/
파이토치로 시작하는 딥러닝 기초
부스트코스 무료 강의
www.boostcourse.org
Overfitting
복잡한(고차원) 모델을 통해 train data를 분류해냈을 때, 너무 train에만 과적합하게 학습된 경우이다.
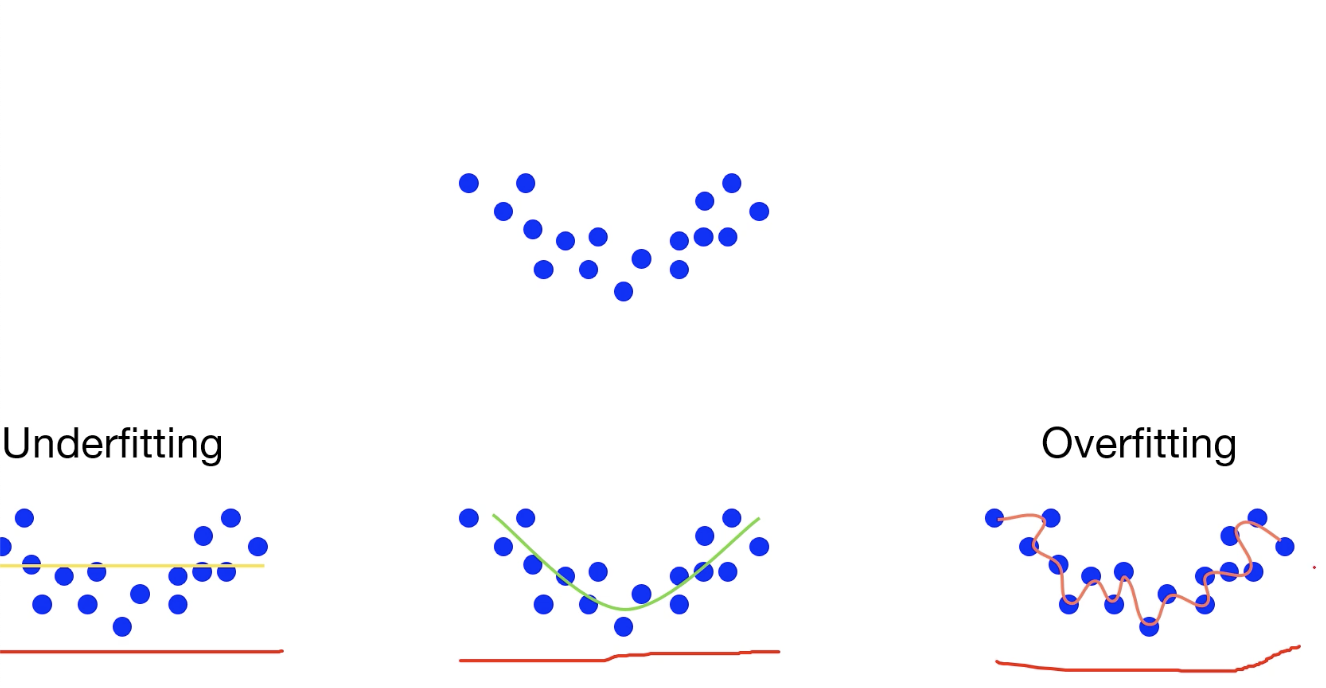
train set과 test set이 완전히 일치하지 않기 때문에 고차원의 모델이 무조건적으로 학습이 잘된 모델은 아니다!
train set에서는 높은 accuracy를 갖지만, test set에서는 낮은 accuracy를 갖는 모델은 overfitting 된 것이다.
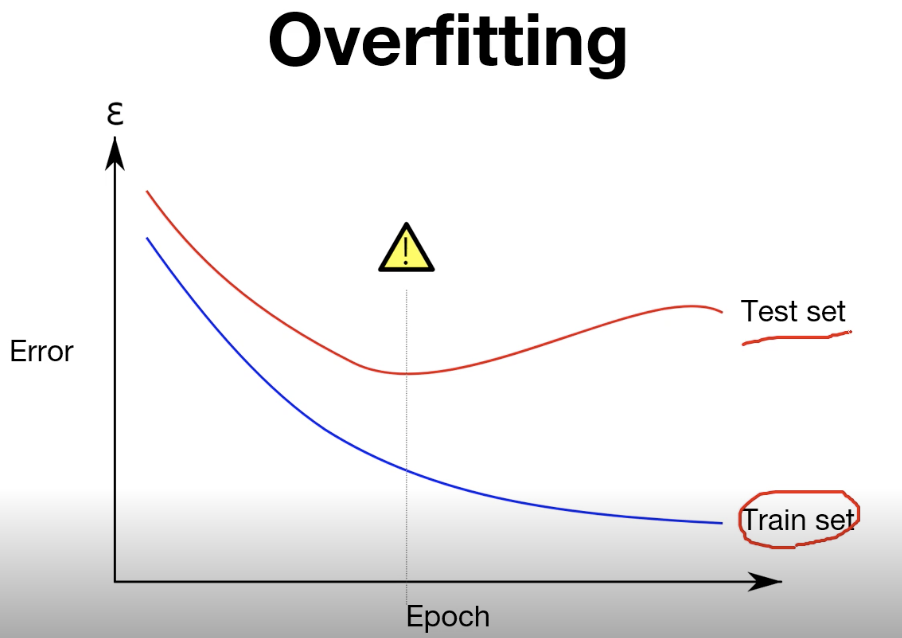
overfitting을 방지하기 위한 방법은 몇 가지 있다!
- train data를 늘린다.
- feature 수를 줄인다.
- regularization 한다.
- dropout한다.
Dropout_overfitting을 해결하기 위한 방법 중 하나
기존에는 학습데이터가 들어오면 전체 weight을 사용하고 activation function을 통해 output을 도출하고 backpropagation으로 weight을 update한다.
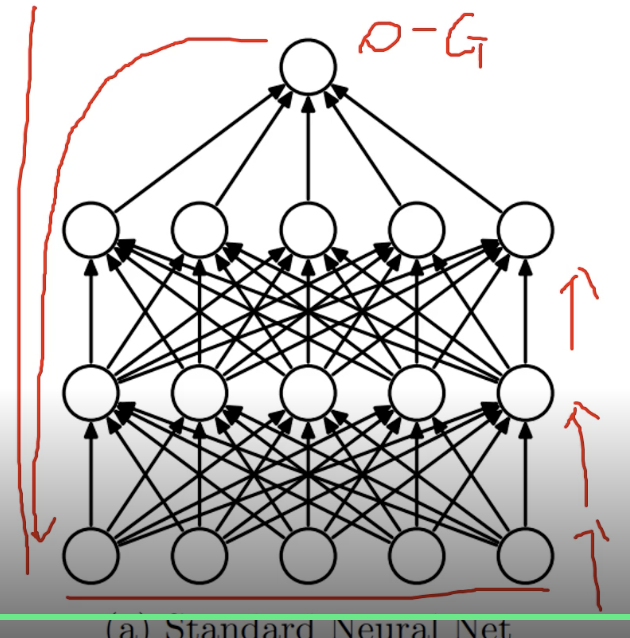
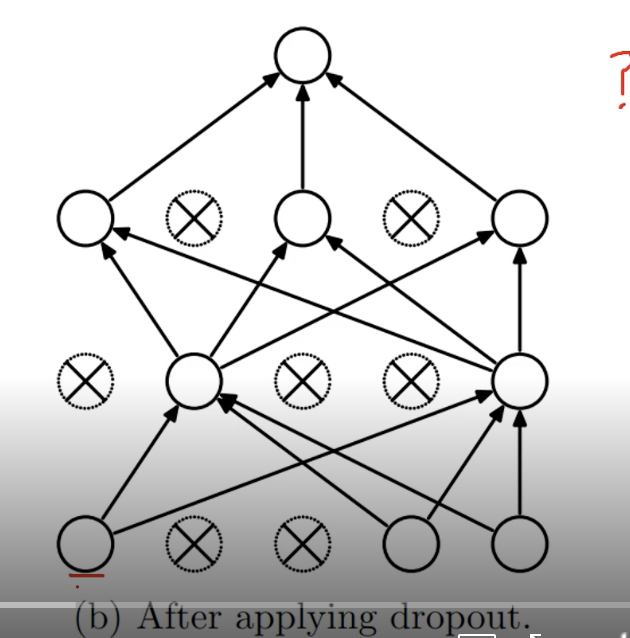
dropout은 학습을 진행하며, 각 layer에 존재하는 node를 특정 비율에 따라 무작위로 껐다 켰다 한다.
x가 주어진 경우, 1.2.3 layer에서 각각 사용하는 node를 무작위로 설정하여, 특정 node의 weight만 사용하며 학습된다.
각 layer별로 얼마의 비율로 사용하고 사용하지 않을지 기준만 설정하면 무작위로 사용할 노드와 사용하지 않을 노드를 설정하낟.
layer를 거치며 학습하고 학습된 결과물 y와 실제값의 loss로 backpropagation하며 weight을 update한다.
--> overfitting 방지가 가능하다.
--> 매번 다른 network 구조로 학습되므로 network 앙상블 효과를 얻을 수 있다.
Code : mnist_nn_dropout
# nn layers
linear1 = torch.nn.Linear(784, 512, bias=True)
linear2 = torch.nn.Linear(512, 512, bias=True)
linear3 = torch.nn.Linear(512, 512, bias=True)
linear4 = torch.nn.Linear(512, 512, bias=True)
linear5 = torch.nn.Linear(512, 10, bias=True)
relu = torch.nn.ReLU()
# dropout 함수를 사용하였다.
# p는 사전에 설정된 확률이다.(위에서 drop_prob는 0.3으로 설정함.)
# 이번 step에서 가지고 있는 node들 중 몇 %를 사용하지 않을지 설정
dropout = torch.nn.Dropout(p=drop_prob)
# xavier initialization
torch.nn.init.xavier_uniform_(linear1.weight)
torch.nn.init.xavier_uniform_(linear2.weight)
torch.nn.init.xavier_uniform_(linear3.weight)
torch.nn.init.xavier_uniform_(linear4.weight)
torch.nn.init.xavier_uniform_(linear5.weight)
# model
model = torch.nn.Sequential(linear1, relu, dropout,
linear2, relu, dropout,
linear3, relu, dropout,
linear4, relu, dropout,
linear5).to(device)
dropout 사용 시 유의해야 할 점이 있다!!
실제 test set을 사용할 때에는 사용할 node, 사용하지 않을 node를 선택하는 것이 아니라, 모든 node를 사용해야 한다.
model.train()과 model.eval()를 주의해서 사용한다.
model.train() -> model안에 모든 layer에서 dropout을 실행하겠다. --> 학습 시
model.eval() -> model안에 있는 dropout을 사용하지 않겠다. (node를 버리지 않겠다.) --> test 시
'''
학습 시
'''
total_batch = len(data_loader)
# 주의!!!!!!!!!! drop out을 훈련할 때는 사용한다!!
# train, test 시 model 사용에 있어서 조심해야 한다!!
model.train() # set the model to train mode (dropout=True)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# reshape input image into [batch_size by 784]
# label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
'''
테스트 시
'''
# Test model and check accuracy
with torch.no_grad():
# 주의!!!!!!!!!! drop out을 테스트할 때는 사용하지 않는다!!
# model.train()이 아니라 model.eval()을 사용하여 test!!
model.eval() # set the model to evaluation mode (dropout=False)
# Test the model using test sets
X_test = mnist_test.test_data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
# Get one and predict
r = random.randint(0, len(mnist_test) - 1)
X_single_data = mnist_test.test_data[r:r + 1].view(-1, 28 * 28).float().to(device)
Y_single_data = mnist_test.test_labels[r:r + 1].to(device)
print('Label: ', Y_single_data.item())
single_prediction = model(X_single_data)
print('Prediction: ', torch.argmax(single_prediction, 1).item())
'인공지능 > 부스트코스_파이토치로 시작하는 딥러닝 기초' 카테고리의 다른 글
| 파이토치로 시작하는 딥러닝 입문 관련 책!! (0) | 2021.02.26 |
|---|---|
| Lab 09-4 Batch Normalization (0) | 2021.02.26 |
| Lab 09-2 Weight initialization (0) | 2021.02.25 |
| Lab 09-1 ReLU (0) | 2021.02.25 |
| Lab 08-2 Multi layer Perceptron (0) | 2021.02.22 |


