
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 2단계
- CS231n
- 이것이 코딩테스트다 with 파이썬
- 그리디
- 구현
- 파이썬
- docker
- SWEA
- 딥러닝
- ubuntu
- cs
- 프로그래머스
- 머신러닝
- Object detection
- MySQL
- Python
- 전산기초
- 백준
- pytorch
- 자료구조 및 실습
- STL
- AWS
- 3단계
- C++
- 1단계
- test-helper
- 모두를 위한 딥러닝 강좌 시즌1
- 코드수행
- ssd
- 실전알고리즘
- Today
- Total
곰퓨타의 SW 이야기
Lab 09-4 Batch Normalization 본문
부스트코스 강의를 수강하면서 작성하였다!!!
www.boostcourse.org/ai214/lecture/43762/
파이토치로 시작하는 딥러닝 기초
부스트코스 무료 강의
www.boostcourse.org
Gradient Vanishing/ Exploding
Gradient Vanishing
Gradient가 너무 작아지면서 소멸하는 문제

Gradient Exploding
Gradient가 너무 크게 발생하면서 생기는 문제
-> DNN의 학습이 어려워진다.
Solution
<간접적인 방식>
Change activation function
-> sigmoid가 gradient vanishing을 야기하므로 ReLU activation function을 사용했었다!
Careful initialization
-> He initialization, xavier initialization 등으로 초기화하는 방법을 사용했다!
Small learning rate
-> gradient exploding인 경우, learning rate를 작게하면 문제를 완화시킬 수 있다.
<쎈 방식>
Batch normalization : gradient vanishing, exploding 뿐만 아니라 학습과정이 stable하고, 학습속도 측면 등에 대해서도 이점이 있다!
Internal Covariate shift
Covariate Shift : neural network를 학습할 때 train, test set으로 나누는데, 아래와 같은 분포를 갖는 train, test set이 있다고 생각하자.
이 둘은 분포가 실제적으로 차이가 있다. --> distribution의 차이가 문제를 발생할 수 있다
(입력과 출력에 대한 분포가 다르므로)

(EX)
고양이 사진이 있을 때 고양이인지 아닌지 구별하는 것이 있다고 가정해보자.
고양이 이미지가 다음과 같은 분포를 가지고 있을 때, 학습을 하며 forward/ backward 작업을 거치는데, 첫 번째 layer를 통과했을 때 covariate shift가 발생할 수 있다. (분포의 변화가 발생한다)
이후의 layer들 또한 통과하면서 internal covariate shift 문제가 발생할 수 있다.
layer가 많을 수록 이러한 문제가 발생할 확률이 커진다..!
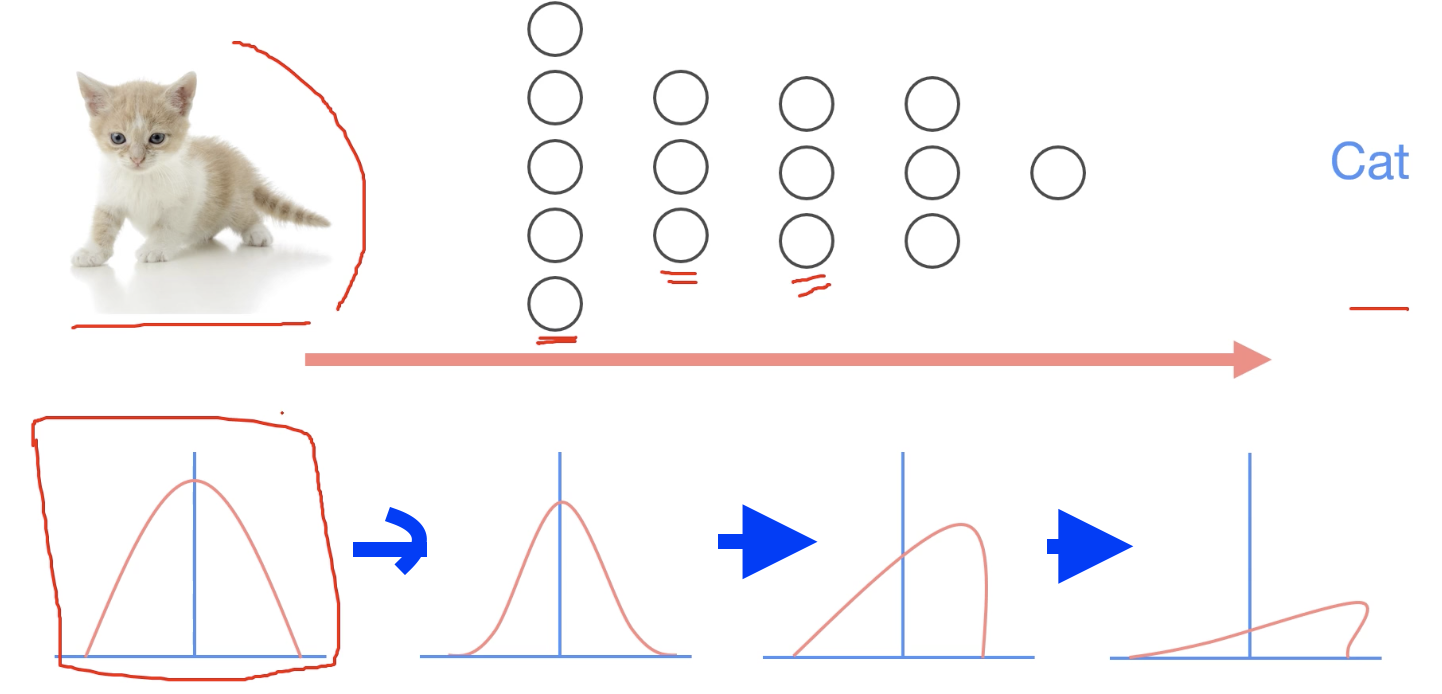
--> 이러한 문제를 해결하기 위해 Batch normaliztaion을 사용한다.
Batch Normalization
internal covariate shift를 해결하기 위해 각 layer마다 normalization을 하도록 하여, 변형된 분포가 나오지 않도록 정규화하는 것이다.
mini batch로 학습을 하므로, mini batch 마다 normalization을 해주겠다는 것이다.
mini-batch의 평균을 구하고, variance를 구한후, normalize한다.
normilize가 끝난 결과에 감마(Γ)를 곱하고 아래에서 shift에 해당하는 β를 더한다.
Γ,β 또한 backporpagation으로 계산하여 학습한다.

dropout 때와 같이 Train&eval mode로 나누어 사용해야 한다!!
어떤 Network가 학습했다고 가정하고 x_test를 test할 때, 평균과 분산을 계산하여 normalize하여 x_hat을 계산한다.
batch normalization으로 학습한 Γ,β 로 결과를 도출한다.
학습할 때 사용한 sample mean, sample normalization을 저장하고, 저장된 sample mean, sample variance를 통해 learning mean, learning variance를 구한다. 이는 sample에 관련없이 변하지 않는 값이다.
test시에도 batch를 사용하지만, batch 마다 다른 평균과 분산을 가질 수 있기 때문에, 이를 극복하기 위해 learning mean, learning variance를 활용한다. test시 batch에 있는 data변화에도 learning mean, learning variance가 변경되지 않으므로 같은 sample에 대해 다른 평균과 분산을 적용하는 것을 방지하기 위해 train과 eval model를 나누어서 사용해야 한다.(이부분은 다시 공부해야할 것 같다.😂)
Code : mnist_batchnorm
이는 github.com/deeplearningzerotoall/PyTorch 에 코드가 정리되어 있어서 이 코드를 fork 하여 주석을 다는 방식으로 공부를 하였다!!
code를 실행하면 다음과 같은 그래프를 도출할 수 있다.
Batch norm을 썼을 때, 사용하지 않았을 때보다 loss가 적게나오는 것을 볼 수 있다.

Batch norm을 썼을 때, 사용하지 않았을 때보다 acc가 더 높게 나오는 것을 알 수 있다.

결론 : batch norm은 좋은 놈이다!!
'인공지능 > 부스트코스_파이토치로 시작하는 딥러닝 기초' 카테고리의 다른 글
| Lab 10-1 Convolution (0) | 2021.02.27 |
|---|---|
| 파이토치로 시작하는 딥러닝 입문 관련 책!! (0) | 2021.02.26 |
| Lab 09-3 Dropout (0) | 2021.02.25 |
| Lab 09-2 Weight initialization (0) | 2021.02.25 |
| Lab 09-1 ReLU (0) | 2021.02.25 |


